The evolution of machine translation
The technology has been around for years, and thanks to its advances we've been able to develop new processes that help us automate processes: optimising both time and resources. The translation sector represents a clear example of how technology has improved processes, helping professionals carry out their work much more efficiently. Getting to this point has been a long process - and it hasn't been easy - which is why we want to dedicate today's post to the progress and evolution of machine translation.
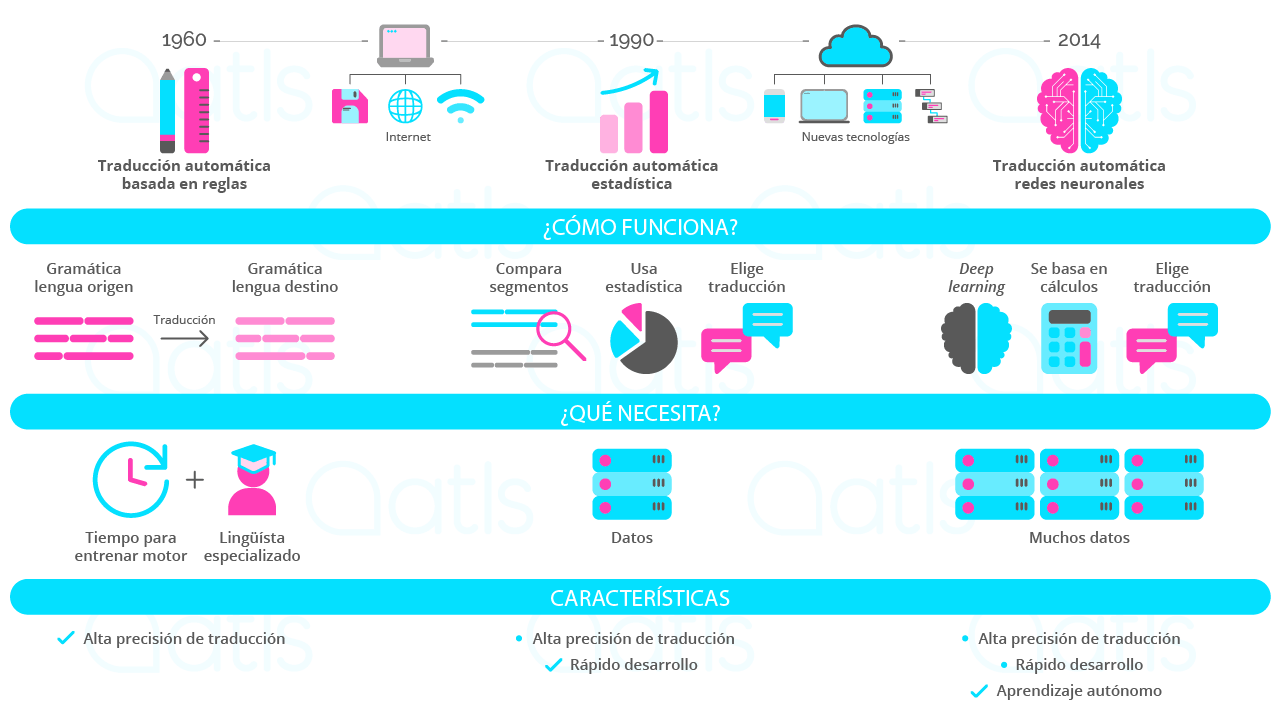
Whilst the roots of this type of translation date back to the fifties, it wasn't until a decade later that the first method of rule-based machine translation appeared. The mechanics were simple: taking a pair of languages, words from the source and target languages were linked together, like a dictionary or glossary: easy, simple, and effective. The system was in use for a number of years as it did yield good results, but in terms of resources it came at a high cost: a lot of time had to be devoted to entering each term, one-by-one.
With the advent of the internet and computers with faster processors, the second method emerged in the nineties: statistical machine translation. This system was faster because it could now employ language databases. Using algorithms and calculations, when it detected a word in the source language the system could show the predicted word in the target language, based on statistics: in other words, if word A had been translated as word B in most cases, the system would choose that word based on probability. This method worked very well for many years - it was fast and fluent and required lower maintenance costs than the previous system.
It wasn't until many years later that the latest method came about - given that it would've been impossible to implement before the era of new technologies and advances in artificial intelligence. 2014 saw the arrival of a model of machine translation model based on neural networks. The key difference between this and the stastitics-based model is that it works in the same way as a human brain creating neural connections. This system takes a huge number of yielded translations in the language pair and makes connections between the terms, linking words or phrases that correspond by employing deep learning: the neural engine has the capacity to predict a translation. One of the advantages of translation AI is that it can be trained and customised to translate from one language to another, and adapt content according to the domain or specialisation, all based on the specific client.
En ATLS hace años que implementamos la traducción automática neuronal para nuestros clientes. We have an enormous amount of data (corpora) from real translations, as well as the required technology (developed internally) which we use to train engines tailored to every client, based on the needs of their specific sector or domain. Contact us and talk us through your situation, and we'll help you find the method that best suits your company and develop a tailor-made solution, just for you.



